
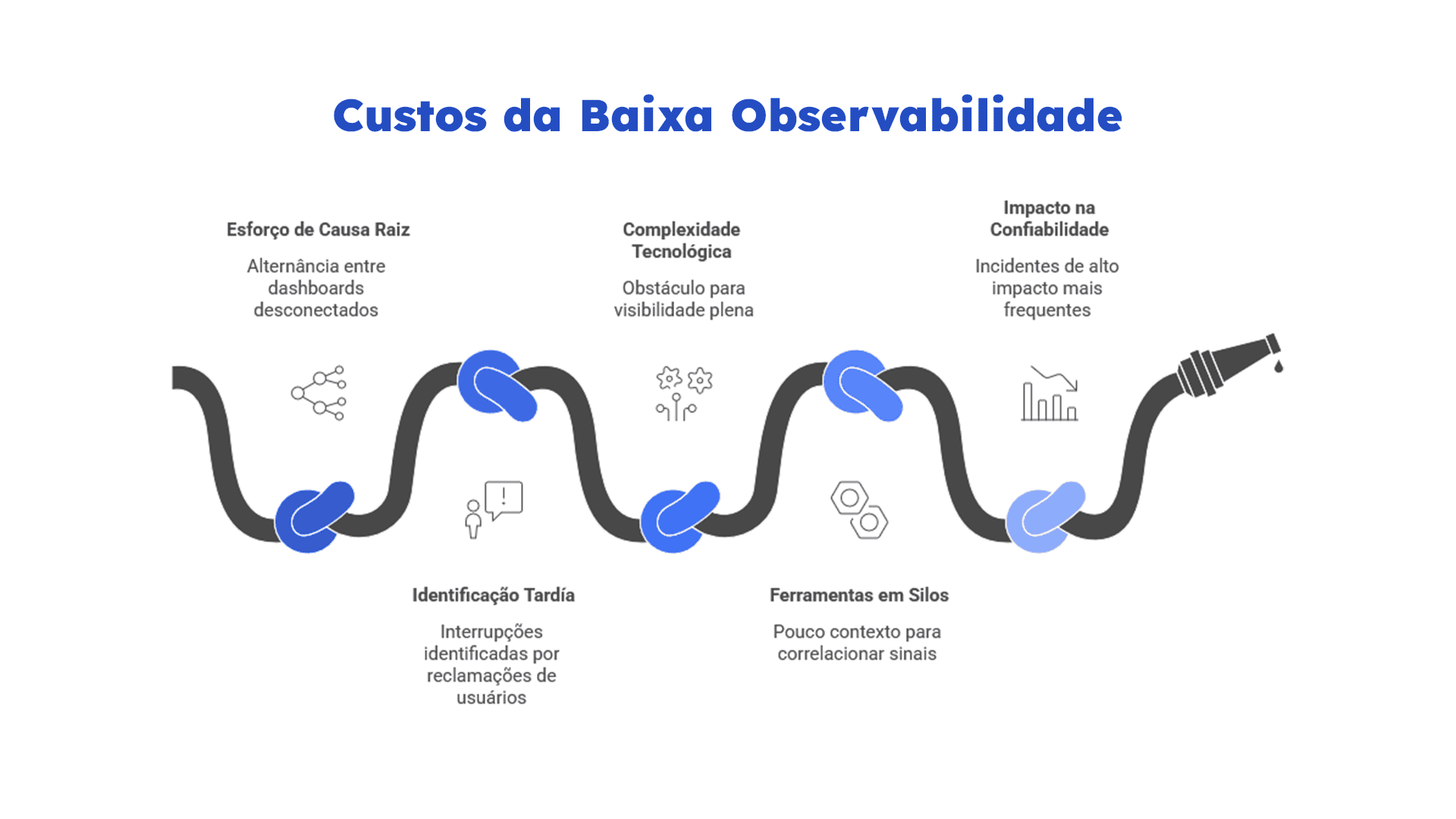
De acordo com o Observability Forecast 2025, um incidente de alto impacto pode custar, em média, US$2 milhões por hora. Ainda assim, o dado mais preocupante talvez seja outro: equipes sem observabilidade full-stack gastam cerca de 168 horas por ano resolvendo incidentes recorrentes — quatro vezes mais do que empresas com visibilidade de ponta a ponta.
O que chama atenção, porém, é que esse problema raramente acontece por falta de ferramenta. Em ambientes distribuídos, é comum encontrar dashboards, alertas e coleta de métricas já implementados. Mas quando algo falha, a pergunta continua a mesma: por que ainda leva tanto tempo para chegar à causa raiz?
Na prática, o gargalo costuma estar na ausência de correlação entre logs, métricas e traces. Sem contexto operacional compartilhado, o troubleshooting vira tentativa e erro, o MTTR cresce e cada incidente exige novamente war rooms e análise manual, um ciclo que, como o dado acima mostra, tem um custo bastante concreto.
É nesse cenário que observabilidade deixa de ser apenas monitoramento e passa a atuar como capacidade operacional. Quando estruturada de forma integrada, ela permite reduzir tempo de diagnóstico, sustentar SLOs e responder a incidentes com evidências e não hipóteses.
 Quer entender como a MarkWay estrutura soluções de observabilidade para ambientes distribuídos e o que muda quando visibilidade operacional passa a ser tratada como parte da estratégia de confiabilidade? Continue a leitura e confira!
Quer entender como a MarkWay estrutura soluções de observabilidade para ambientes distribuídos e o que muda quando visibilidade operacional passa a ser tratada como parte da estratégia de confiabilidade? Continue a leitura e confira!
Como a MarkWay estrutura a implementação de observability em ambientes reais
Uma das armadilhas mais comuns em projetos de observabilidade é tratar a iniciativa como uma instalação de ferramentas. Define-se um stack, sobe-se o Grafana, configuram-se dashboards e parte-se do pressuposto de que a visibilidade está resolvida. O resultado costuma ser o oposto: alertas sem contexto, troubleshooting prolongado e dependência de especialistas para interpretar sinais desconectados.
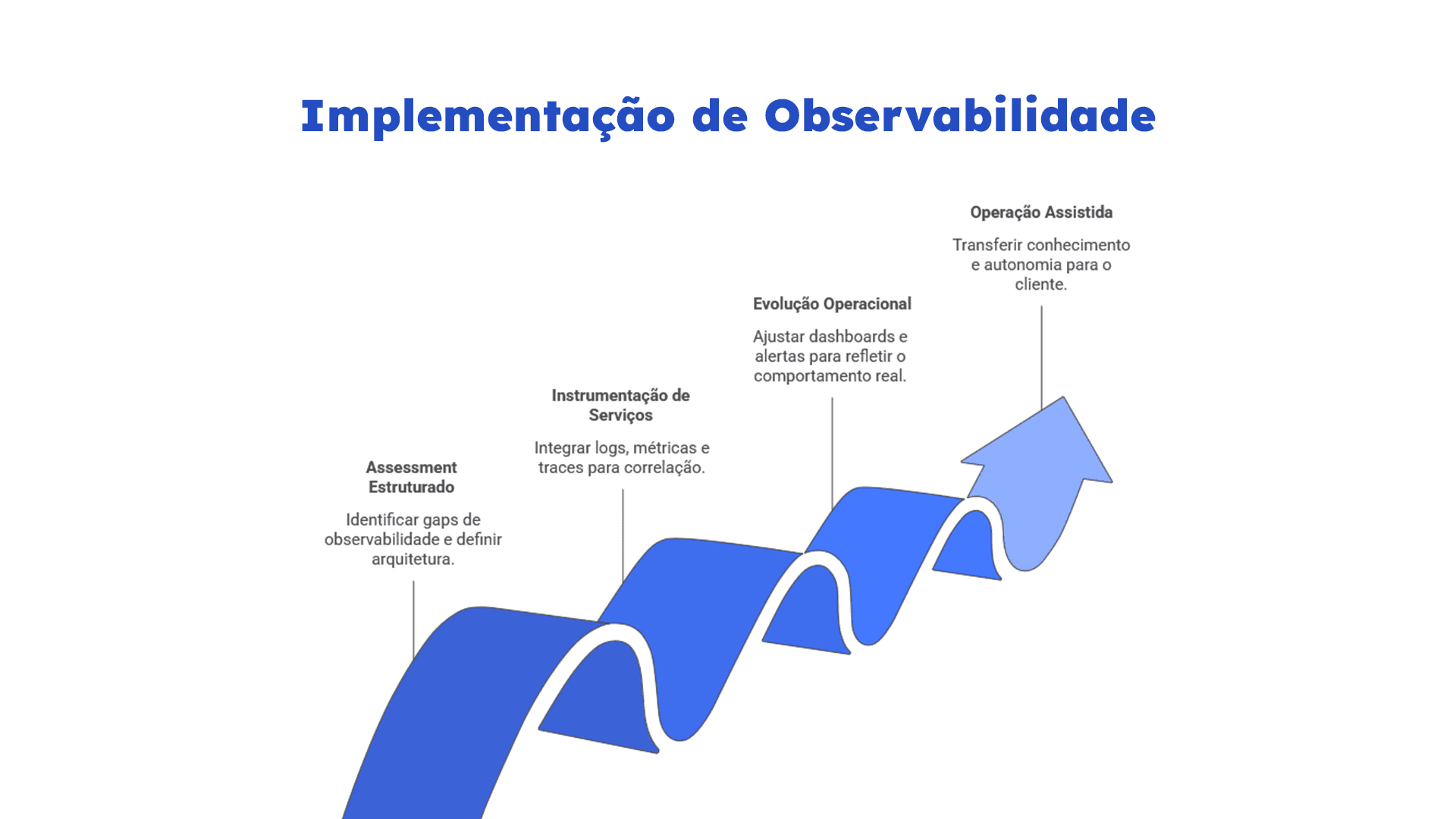
 Por isso, a abordagem da MarkWay começa antes da escolha tecnológica. O primeiro passo é um assessment estruturado do ambiente, com foco em identificar gaps de observabilidade, dependências críticas, limitações de instrumentação e requisitos de confiabilidade. É nessa fase que se define qual arquitetura faz sentido para o contexto operacional do cliente.
Por isso, a abordagem da MarkWay começa antes da escolha tecnológica. O primeiro passo é um assessment estruturado do ambiente, com foco em identificar gaps de observabilidade, dependências críticas, limitações de instrumentação e requisitos de confiabilidade. É nessa fase que se define qual arquitetura faz sentido para o contexto operacional do cliente.
Com a arquitetura definida, o projeto avança para a instrumentação dos serviços críticos. Logs, métricas e traces passam a compartilhar contexto operacional, permitindo correlação entre sinais ao longo de toda a cadeia de uma requisição. Para acelerar esse processo, a MarkWay utiliza padrões de implementação já validados em aplicações Java, clusters Kubernetes, bancos de dados e mensageria e componentes recorrentes de infraestrutura, reduzindo o tempo de setup sem abrir mão de consistência na coleta.
A partir daí, a observabilidade entra na fase de evolução operacional: dashboards passam a refletir o comportamento real dos serviços, alertas são ajustados para reduzir ruído e SLIs/ SLOs começam a ser definidos com base em evidências de produção, criando a base para práticas mais maduras de confiabilidade operacional, como SRE (Site Reliability Engineering), especialmente em ambientes onde disponibilidade e experiência do usuário têm impacto direto no negócio. O objetivo deixa de ser visualizar métricas e passa a ser responder incidentes com contexto suficiente para reduzir MTTR e acelerar o RCA.
Já a fase final é a operação assistida em que o ambiente é acompanhado de perto enquanto o time do cliente ganha autonomia sobre a stack. Esse processo inclui documentação técnica, runbooks e transferência gradual de conhecimento, estruturada para evitar que a visibilidade conquistada fique presa em dependência de especialistas externos.
Stack aberta ou solução proprietária: como tomar a decisão certa?
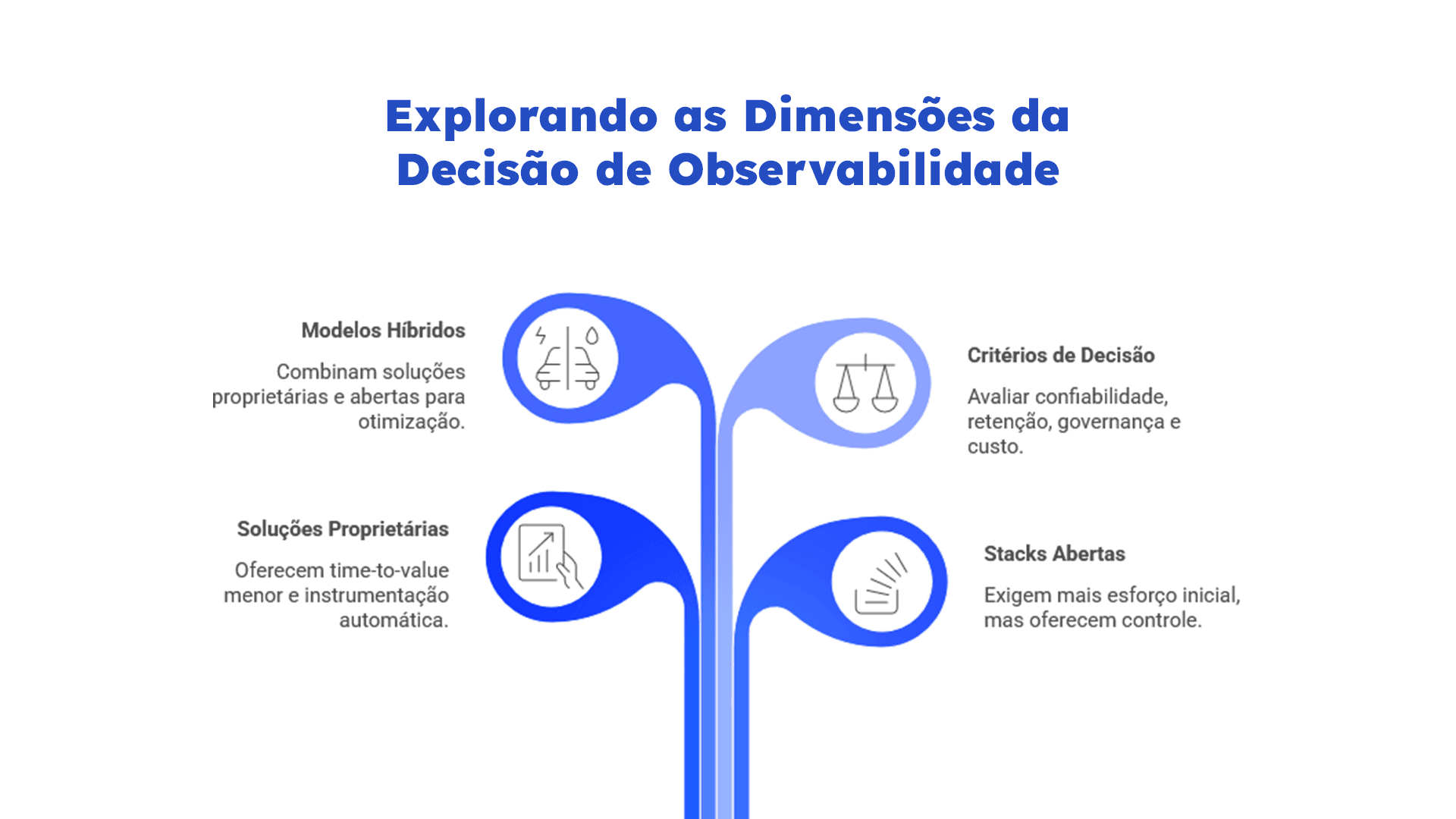
Uma das perguntas mais frequentes em projetos de observabilidade é também uma das mais importantes: vale mais investir em uma solução de mercado, como Dynatrace ou AppDynamics, ou construir uma stack baseada em OpenTelemetry, Prometheus e Grafana? A resposta honesta é: depende. E qualquer fornecedor que responda diferente provavelmente está oferecendo o que tem, não o que você precisa.
Soluções proprietárias costumam oferecer time-to-value menor. A instrumentação automática reduz o esforço inicial, a correlação entre sinais já vem parcialmente pronta e o suporte a ambientes legados tende a ser mais maduro. O trade-off normalmente aparece em dois pontos: custo e flexibilidade. À medida que logs, métricas e traces passam a depender de uma plataforma proprietária, o grau de acoplamento ao vendor aumenta, impactando assim desde retenção de dados até a capacidade de evoluir a arquitetura sem depender do roadmap da ferramenta.
Stacks abertas seguem uma lógica diferente. Combinações baseadas em Open Telemetry, Prometheus, Grafana, Loki e Tempo exigem mais esforço inicial, mas oferecem maior controle sobre os dados e evolução mais modular. Além disso, o Open Telemetry já se consolidou como padrão vendor-neutral, suportado por dezenas de plataformas comerciais e open source. Isso permite instrumentar uma vez e direcionar telemetria para diferentes backends sem refazer implementação.
Na prática, os dois modelos não são excludentes e é até bastante comum encontrar ambientes híbridos com OpenTelemetry como padrão de instrumentação, Grafana para visualização operacional, Elasticsearch para retenção de logs ou até plataformas proprietárias consumindo telemetria aberta. O ponto central não é escolher entre open source ou vendor, mas definir qual combinação atende melhor os requisitos de confiabilidade, retenção, governança, custo e capacidade do time de sustentar a stack ao longo do tempo.
 Na MarkWay, a definição tecnológica acontece depois do assessment. Independentemente do caminho, o critério permanece o mesmo: construir uma camada de observabilidade que o time consiga operar, evoluir e utilizar para reduzir MTTR, sustentar SLOs e responder incidentes com contexto real e não apenas com mais dashboards.
Na MarkWay, a definição tecnológica acontece depois do assessment. Independentemente do caminho, o critério permanece o mesmo: construir uma camada de observabilidade que o time consiga operar, evoluir e utilizar para reduzir MTTR, sustentar SLOs e responder incidentes com contexto real e não apenas com mais dashboards.
Conheça nossos cases de implementação de observabilidade
Embora os desafios mudem de setor para setor, alguns padrões se repetem. Em alguns dos projetos conduzidos pela MarkWay em ambientes de saúde, energia e previdência, para citar alguns, os contextos técnicos eram diferentes, mas os gargalos operacionais apareciam com frequência semelhante: monitoramento fragmentado, troubleshooting prolongado e forte dependência de conhecimento tácito para RCA.
| Setor | Contexto da operação | Abordagem aplicada | Resultados obtidos |
| Saúde | Ambiente com múltiplos microsserviços e clusters Kubernetes sem visibilidade centralizada, alto volume de alertas sem contexto suficiente para priorização e dependência de conhecimento tácito para diagnóstico de incidentes | Implementação da Grafana Stack (Grafana, Loki, Tempo e Prometheus) com instrumentação via OpenTelemetry, cobrindo aplicações, infraestrutura e pipelines de dados | Centralização de logs, métricas e traces em ambiente unificado, redução de cerca de 40% no MTTR após a centralização de traces e logs estruturados e diminuição da dependência de pessoas-chave para RCA |
| Energia | Infraestrutura distribuída entre datacenter e cloud com monitoramento fragmentado por ferramenta, dificuldade de correlacionar eventos entre camadas e pressão crescente por SLA de disponibilidade | Assessment de gaps seguido de instrumentação padronizada com OpenTelemetry, estruturação de SLIs e SLOs para os serviços críticos e criação de dashboards operacionais com alertas ajustados | Aumento de disponibilidade, redução de incidentes críticos em produção e melhoria na performance de latência e throughput dos serviços monitorados |
| Previdência | Sistemas legados e modernos operando em paralelo, sem rastreabilidade de ponta a ponta sobre requisições e com dificuldade de identificar causa raiz em falhas que atravessavam múltiplas camadas | Implementação de tracing distribuído com correlação entre logs estruturados e métricas, cobrindo tanto os serviços modernos quanto as integrações com sistemas legados | Melhoria na rastreabilidade operacional, redução do tempo médio de resolução de incidentes e maior previsibilidade sobre o comportamento dos sistemas em produção |
Vale destacar que, nos três contextos, os projetos foram conduzidos em diferentes áreas do mesmo cliente ao longo do tempo, o que reflete menos uma expansão comercial e mais um resultado prático: quando a visibilidade melhora em uma área, outras partes da organização passam a enxergar o mesmo problema com mais clareza.
Conte com a MarkWay para a sua implementação de observabilidade
A MarkWay atua desde o assessment inicial até a instrumentação, evolução operacional e transferência estruturada de conhecimento, com experiência em ambientes críticos nos setores de saúde, energia e previdência.
 Em muitos casos, o ponto de partida mais comum é o assessment de observabilidade: um diagnóstico estruturado para mapear gaps de visibilidade, identificar limitações da stack atual e definir qual arquitetura faz sentido para o seu contexto, sem partir da premissa de que uma ferramenta específica já é a resposta certa.
Em muitos casos, o ponto de partida mais comum é o assessment de observabilidade: um diagnóstico estruturado para mapear gaps de visibilidade, identificar limitações da stack atual e definir qual arquitetura faz sentido para o seu contexto, sem partir da premissa de que uma ferramenta específica já é a resposta certa.
Se o troubleshooting no seu ambiente ainda consome tempo excessivo, os alertas geram mais ruído do que contexto ou o MTTR permanece acima do esperado, provavelmente existe um gap de observabilidade que vale investigar.
Fale com um especialista da MarkWay e entenda como estruturar uma estratégia de observabilidade alinhada à complexidade do seu ambiente.
{kind=link}